
Harness engineering is not a moat
it's good software engineering foundations

A couple of years ago, prompt engineering was going to be a career. Then the models got good enough that the tricks stopped mattering, and the job evaporated before it really arrived. Nowadays, it’s all about harness engineering, the scaffolding around the model: how it reasons, calls tools, manages context, remembers, checks its work. So it’s worth asking: will harness engineering have the same fate as prompt engineering?
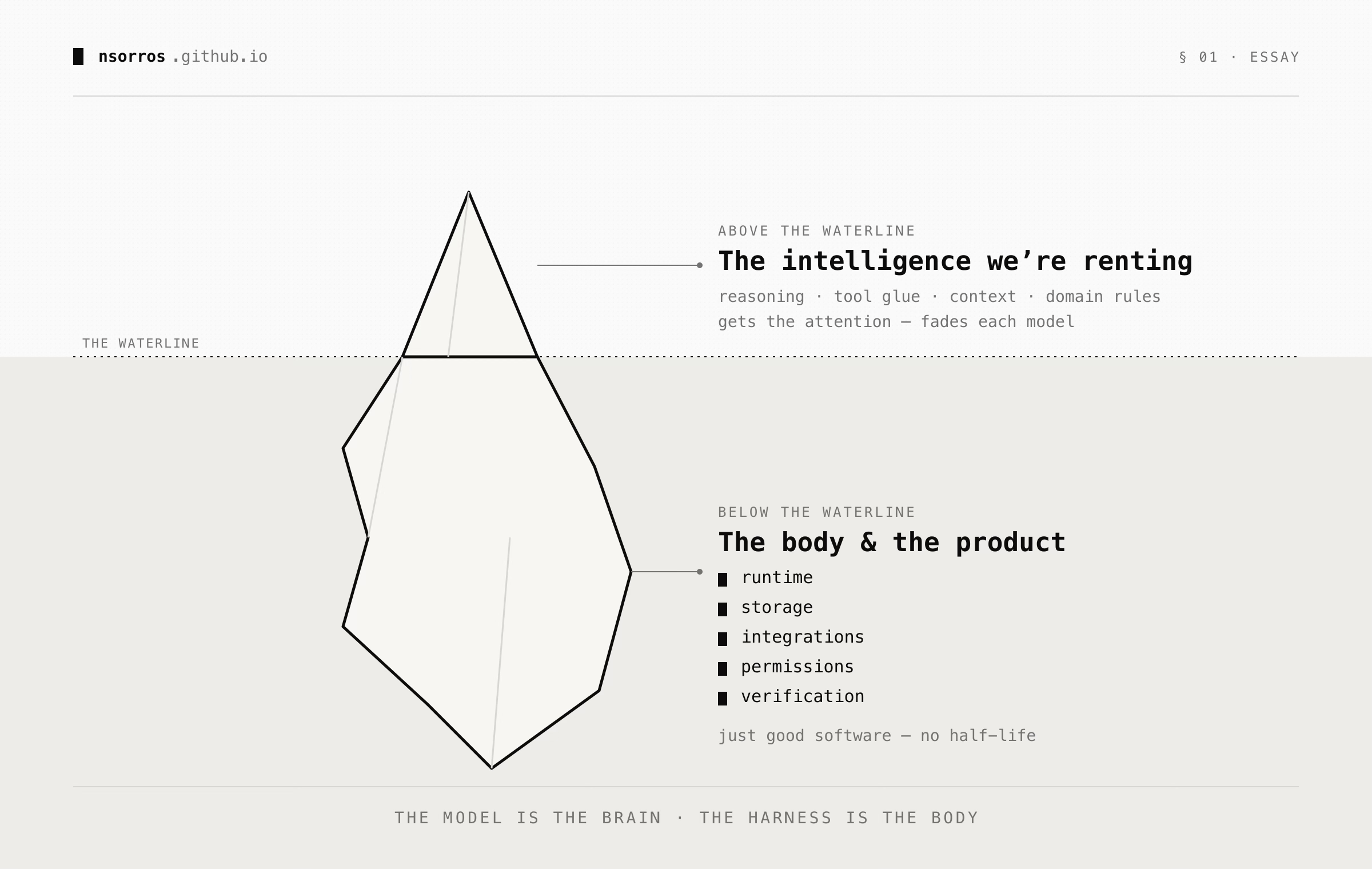
This is not to say that the harness is not important because it is. It is what turns your AI model into an agent. However, it currently serves two distinct roles, one of which gets more publicity and is more important in the short term, with the other being the core of what stays. Let’s start with the first.
Patching limitations of current models
One of the main reasons, harness engineering is getting a lot of attention is because it makes an existing model perform better on a task. That on its surface seems valuable and can be mistaken for long term business value. However, I don’t think most of those fixes are here to stay. Here is a list of such fixes, some of which are already obsolete:
🤔Reasoning like chain-of-thought, self-reflection loops (Reflexion, Self-Refine). Before reasoning models, there were plenty of techniques that were making models better at thinking which had a downstream effect in real world tasks, coding included but nowadays models are trained to reason so these techniques got removed from the harness level.
🛠️ Tools. Early harness code was also fixing issues with tool use, format the call, parse output, retry bad JSON. Models choose and call tools cleanly now, the skill is being internalised. Tools choice still matters but it plays an ever smaller role as models become better at making the right choice by themselves.
💿 Context. Pruning, compacting, pulling key facts back is where a lot of today’s lift sits. Manipulating the context is the latest art form. Bringing the right tools closer to the context, keeping the right information etc and suddenly your agent starts performing much better. However models are already getting better at managing their context so I am not so sure this will be an important part of future harnesses.
🏭 Domain knowledge is the single biggest lever right now. The reason being that current models, even though excellent at most domains, they lack on the job experience in your, or any, company. This means that there is plenty of room for adjusting how the agent performs in the tasks that are important to you. I am under the impression though that this will also go away when companies devise agent onboarding materials that the agent can refer back to.
In any case, it is important to be sceptical about additions to the “intelligence“ layer that will very likely go away at the next model iteration.
The agent runtime
The other role of the harness is more boring but more important in my opinion. It is the part that runs the AI model. This is the orchestration in some way, the software engineering engine around AI. It’s more the product than the intelligence itself. It contains things like
⚙️ Runtime. The engine that actually executes the model and its tools, reliably and at a sane cost. A smarter model still has to run somewhere, and keeping it up, retrying what fails and not blowing the budget on tokens is plain infrastructure work that no model iteration takes away.
💾 Storage. Sessions and memory have to live somewhere, which gives you an auditable trail of what the agent did but also the substrate for it to improve over time. However much a model can hold in its head, it still needs a notebook outside of it.
🔌 Integration surface. The access to your systems and data, and the ability to take real actions in the world. A brain with no hands does nothing, and wiring up those hands is ordinary software engineering that only grows as the agent is trusted with more.
🔒 Permissions and policies. The guardrails around what the agent can and cannot do, what it can touch, spend or send. The more capable the model gets the more this matters, not less, because a smarter agent left unchecked can do more damage and do it faster.
✅ Independent verification. One model doing the work and another checking it, because a model grading its own output goes soft the same way you shouldn’t review your own PR. This is a product decision about trust, not a trick to squeeze more intelligence out of the model.
So what do you do?
I would start by separating the above two aspects of the harness. The intelligence uplift , context juggling, the domain rulebook which is a tune, not a moat: the same kind that prompt engineering and fine-tuning gave. Don’t over invest in it, as it is a depreciating asset.
The durable element of the harness is the other half, the body and the product around the model brain. . That’s just good software engineering, and good software engineering is here to stay.

Pay attention: LLMs are finding real, unknown vulnerabilities now - Google reported the first known in-the-wild case of attackers using an LLM to discover a previously unknown vulnerability, and the UK AI Security Institute now clocks top models executing attacks that would take a human ~3 hours (up from a 1-hour forecast, and 30 minutes at Opus 4.6’s debut). The patch-vs-exploit math has changed, and LLM-found logical flaws are an active threat rather than a forecast.
Skip: All model labs are now agent labs - The whole industry capitulated to the harness in one news cycle (OpenAI, AI21, even DeepSeek), and the scary version of the story is that labs co-train models to only work inside their own agent, but I’m not convinced the lock-in bites, because even if the raw model stops being freely swappable, the agent layer on top of it probably still is.
Skip: The labs are moving into the consulting lane - OpenAI bought a 150-person FDE shop and Google joined the hiring spree, but labs chasing services revenue is just gravity, and unless you’re a consultancy or a thin wrapper you’re fine. The more useful takeaway is that the AI part itself won’t be your differentiator for much longer, because everyone, the labs included, is racing to embed it everywhere.
Skip: “Flash” is no longer the cheap tier - Gemini 3.5 Flash landed at frontier-class scores but 5.5× the price of its predecessor, so the “Flash = cheap” heuristic is not relevant anymore. At the same time, if you specifically need the speed, Flash is the fastest model on its intelligence level
Skip: An OpenAI model disproved an 80-year-old Erdős conjecture - A general-purpose model produced a genuinely novel result in under $1,000 of compute, a great story of AI scratching the surface of what’s possible, but it doesn’t change any practical use case you will build.