
The tale of the rabbit and the turtle
How AI might not be making us as productive as we think

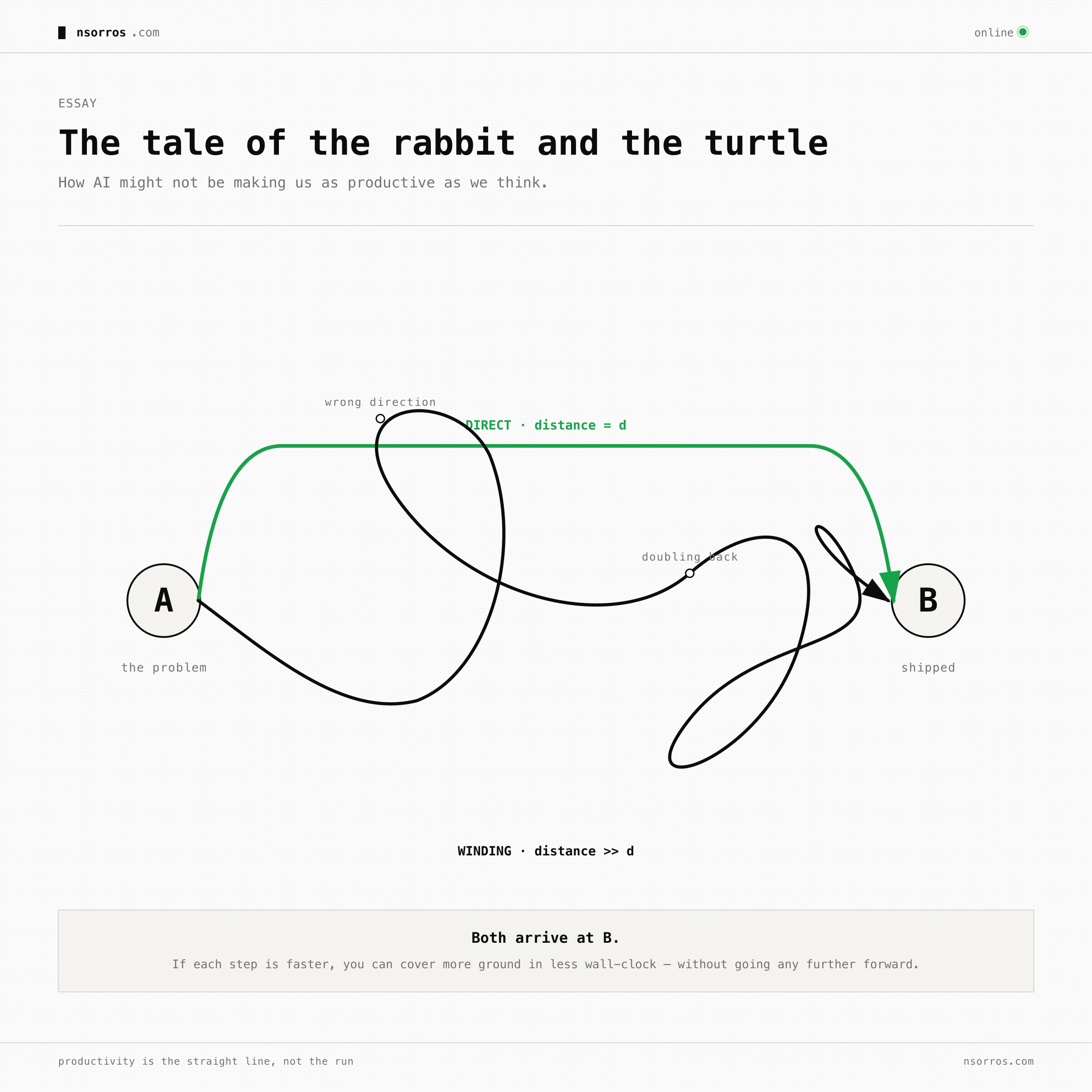
We feel more productive with AI. We’re shipping thousands of lines a day. Whole apps and complex features are built in front of our eyes in a few hours, work that would have taken weeks pre-2024. The rabbit is fast. But how much faster are we actually going from A to B? And what if we’re moving faster down a longer road?
The mental model is the product.
When you program, a big part of the work isn’t typing code. It’s fitting what already exists, and what needs to exist, into your head, and coming up with a solution that delivers the result in a way that is clean, extensible, and consistent with what the owner of the ticket actually wants. The output you’re really producing is the mental model of the system. The code on the screen is a side effect of having that model in place. Asking an AI agent to do the work, while under specifying how or what needs to be done, breaks that. The mental model isn’t getting built, the AI is filling in the gaps with its own assumptions about your intent. And that doesn’t speed you up, because you’ll eventually need to sync mental models with the system anyway. You’ll still have to decipher what got built and confirm it matches what you wanted.
The difference is that now you do this iteratively. The AI produces something, you look at it, you realize you actually wanted X not Y, you tell it to adjust, it produces a new version, you refine again until you converge. Every individual step feels fast. But are you faster, or are you just moving fast down a longer road?
This isn’t speculation. Researchers and engineers building with AI are converging on the same observation, and proposing different responses, spec-driven development, agent scaffolding, treating the LLM as a junior engineer who needs a tight brief. What matters in practice is being able to inspect whether you’re in this situation and mitigate when you are. There’s no clean, well-proven solution yet. So here are some thoughts and observations from my own coding journey with AI.
How can we measure this?
The question is whether we are under specifying and paying the price by rewriting too much of our code too often. At the same time we want to know if some metric of business value or product velocity has meaningfully ticked upwards. Here is one way to quantify them (by no means the only or the right one)
Code half-life. Of the code you wrote N weeks ago, what percentage is still alive in the codebase today? A high half-life means the code you ship sticks. A collapsing half-life means you’re rewriting too often.
Adjustment rate in your AI sessions. What fraction of your AI coding sessions are refinements of prior AI output i.e. “remove what you added,” “different approach,” “also do X”, versus brand-new scope or status checks? A pre-AI analog exists too: PR descriptions and commit messages with fix: / refactor: / revert: prefixes.
Story points (externally validated). How many units of real value are landing per unit time? If you have a PM, a customer, or any external system that quantifies what was actually delivered, that’s one metric that speaks to increased product velocity or business value. This one is also harder to fake than the other two.
The three together are one way of trying to measure if you are moving faster towards a straight line or doing circles to reach the same destination. Writing less code raises half-life but tanks tasks shipped. Accepting whatever the AI produces lowers adjustment rate but tanks half-life. Only “specify up front, ship deliberately” pulls all three in the right direction at once. Here is how those metrics look for two of my projects. Project A is a pre-AI codebase while Project B is post-AI.
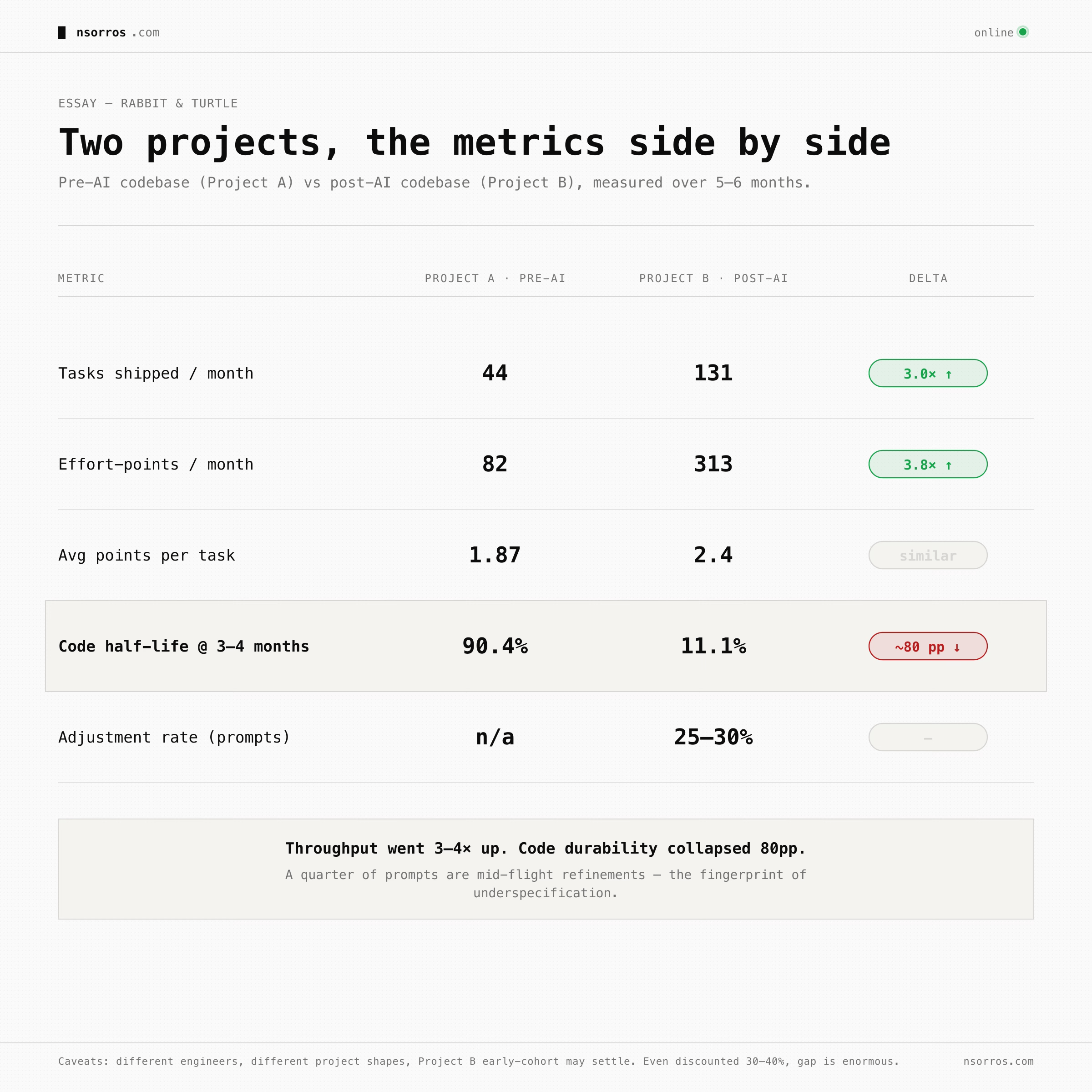
Throughput is way up. No ambiguity 3–4× more shipped per month, with similar effort per task. The rabbit is faster. But the durability collapsed. Code that should be settled by month four has been rewritten down to 11% of itself. And about a quarter of my prompts to Claude are refinements after the fact.
So how do you make the rabbit win?
What my data and others’ suggest is that you should treat speed-of-generation as a tax base, not a finish line. The tax you pay is in churn and rewrites. The way to lower the tax is upstream, by spending more time building a mental model first, so that what the AI does isn’t something that will require ten passes of refinement.
The turtle isn’t slow because it types slowly. It’s slow because it thinks before it moves. The rabbit can move much faster but it only wins the race if it spends enough of its speed advantage on knowing where it’s going.
Three signals to start with: code half-life, adjustment rate, externally-validated points shipped. Measure them, watch the trend, and see whether your road is getting straighter or just longer.

Pay attention: OpenAI deprecates finetuning APIs. Fine tuning was an important lever for improving models till very recently. This marks the end of an “era“ in some sense.
Pay attention: Anthropic meters programmatic Claude usage. Anthropic, and other labs have been subsidising subscription usage but it looks like the end of this might be coming closer so definitely worth planning for a future where token pricing and subscription are more equal.
Pay attention: METR - speed up, value up… less. Yet another study that speaks to the rabbit and turtle phenomenon of speeding up code development does not necessarily translating to real productivity gains
Skip: DeepMind AI Co-Mathematician - I would not pay too much attention on harness and manual gains on top of latest models that might become irrelevant as soon as the next version launches.
Skip: Interaction Models (Thinking Machines Lab) - A super interesting work with questionable real world use cases, at least not as many.